
현재 문제 : 컬렉션을 페치 조인하면 페이징이 불가능하다.
(되긴하는데 일대다 에서 다쪽으로 페이징이 된다. -> 우리는 일쪽으로 페이징하고싶다.) - 바로 전강의에 나온내용.
# 해결책

일단 Order와 ToOne 관계인 것은 Member, Delivery 이다. (item은 orderitem거쳐야하므로 뺀다.) (이미 orderitem에서 늘어난 row와 매핑)
ToOne관계는 fetch join 계속 걸어도된다.(데이터뻥튀기안된다. (데이터 row수는 변화없음. 옆으로 칼럼만 붙는다.)
1. -> 결국 ToOne 까지(Delivery) 까지만 fetch join하자
(이러면 일단 order, member, delivery 는 한 방 쿼리로 가져올 수 있다.) - 이해 안되면 페치조인모르는 거임
2. 컬렉션은 지연 로딩으로 조회한다.
- LAZY로 그냥 둔다.
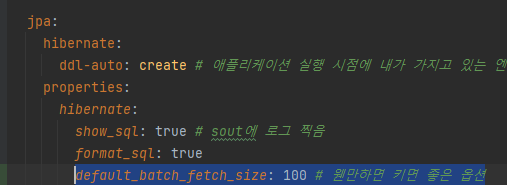
3. 지연로딩을 최적화하여 가져오는 방법
'hibernate.default_batch_fetch_size', @BatchSize
# 1. -> 결국 ToOne 까지(Delivery) 까지만 fetch join하자
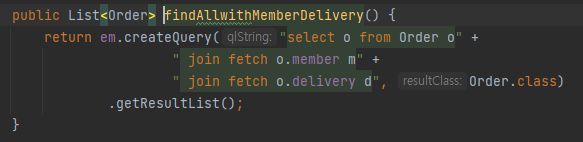

이렇게 하면 쿼리 몇개 나갈까? 바로 맞췄음.
(order,member,delivery), orderitem, item, item, orderitem, item, item -> 총 7번
(member, delivery는 페치조인했으므로 한번의 select가 나감.)
-> 1 + N + N 상태.
# ToOne 페치조인, 페이징
페이징 : 데이터 나눠서 응답

offset은 첫번째 건너뛰고 몇번째부터 (첫장은 0)
limit은 개수제한 (100페이지까지)
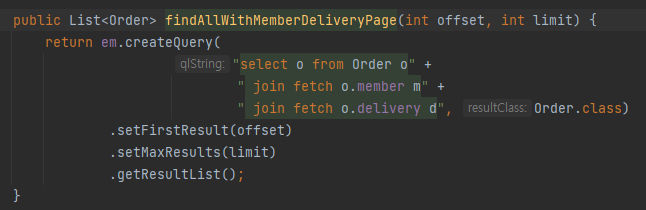
.setFirstResult 와 .setMaxResults 를 활용하여 페이징처리한다.
총 페이지수, 등등 여러 메서드 있음.

결과 userB 꺼만 나옴. -> 왜?? offset이 1 이므로(시작은 0) 그리고 100개 까지 페이지가 있는데 데이터가 단 두개 므로 첫번째꺼 빼고 반환.
이 때 쿼리 : (Order,Member,Delivery) -> orderitem -> item -> item
페이징 되었기 때문에 1개의 orderitem만 넘어왔다.
offset : "0" 이었으면
이 때 쿼리 : (Order,Member,Delivery) -> orderitem -> item -> item -> orderitem -> item -> item
=====
-> 쿼리 더 줄여보자!
2. 지연로딩을 최적화하여 가져오는 방법 'hibernate.default_batch_fetch_size', @BatchSize
이 떄 쿼리:
(Order,Member,Delivery) -> orderitem -> item
여기서 orderitem을 보면 in 쿼리가 나가있다. (orderitem에서 item에 대해 각각 쿼리를 날렸지만 )
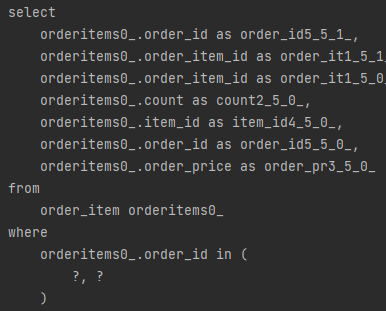
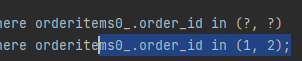
order_id인 1,2 가 들어가있다.
-> in쿼리로 한번에 DB에있는 memberA의 item, memberB의 item들을 한번에 가져옴.
위의 application.yml 에서 설정했던 default_batch_fetch_size : 100 에서 100이 in 쿼리 수를 설정하는 것이다.
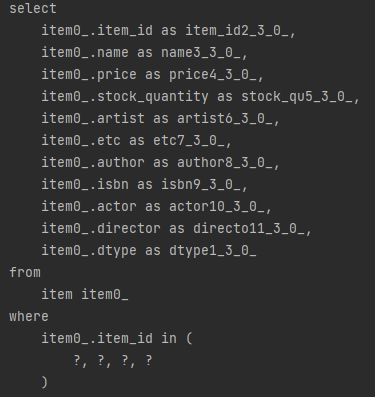
item은 4개를 다 땡겨온다. 와 신기하다.

이렇게 하니까
1:N:M 이 1:1:1 이 되어버림. -> 어마어마한 최적화
웬만하면 원하는 성능 나옴
진짜 실시간 고객정보 조회해야하는 시스템은 레디스써야지
컬렉션페치조인 + hibernate.default_batch_fetch_size
=> 이 방법을 쓰니 성능최적화 + 페이징
=> 물론 v3 보다는 쿼리 많이 나감.(v3은 한방쿼리) but v3은 페이징 불가
# V3(전부다 페치조인) vs. V3-1 (XToOne 만 페치조인)
1. V3(전부다 페치조인) 쿼리

V3의
장점: 쿼리가 하나로 나감
단점 : 중복데이터가 많은데 이걸 DB에서 애플리케이션으로 다 전송함. (일대다(컬렉션) 조인하면 다 개수만큼까지 데이터가 늘어남 -> 용량이 많아짐.)
2. V3-1 (XToOne 만 페치조인) 쿼리
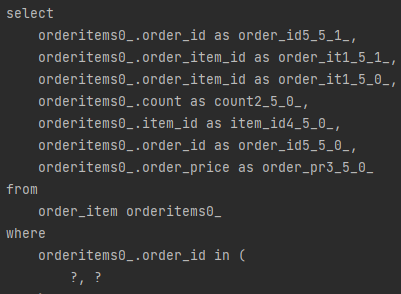
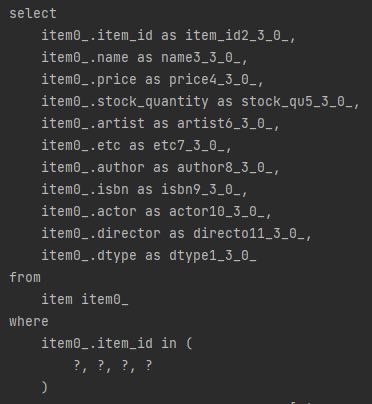

장점 : 데이터가 최적화되어 전송된다.(정확하게 중복이없는 데이터가 전송된다.) - 테이블 단위로 in쿼리찍어서보내기때문
단점 : 쿼리 3개?
==> 영한님은 3.1방식 많이 쓰신다.
# 번외

XToOne 의 페치조인 지원도 default_batch_fetch_size 에 의해
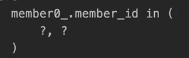

이런식으로 in쿼리로 다잡아서 가져오는데 네트워크를 더 많이 탐.
그냥 XToOne 관계는 페치조인 적어두는게 좋다.! (XToOne은 데이터뻥튀기 안된다.)
# default_batch_fetch_size vs @BatchSize
@BatchSize는 각각에 적용. 컬렉션의 경우 필드 위에 적고, XToOne의 경우 엔티티클래스 위에 적고 size적는다.
=> 근데 보통 글로벌 설정인 default_batch_fetch_size 쓴다.
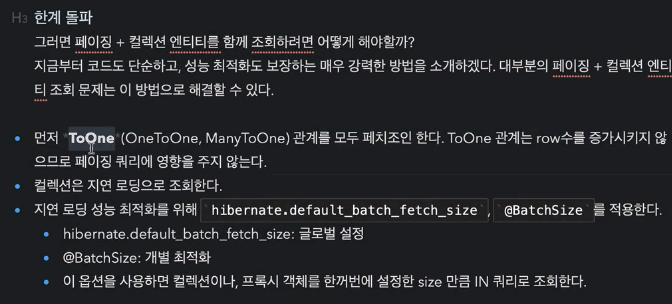

# 결론 : ToOne 관계는 페치조인해도 페이징에 영향을 주지 않는다. 따라서 ToOne 관계는 페치조인으로 쿼리 수를 줄이고 해결하고, 나머지(컬렉션) 는 hibernate.default_batch_fetch_size 로 최적화하자.
# 결론 : ToOne 관계는 페치조인해도 페이징에 영향을 주지 않는다. 따라서 ToOne 관계는 페치조인으로 쿼리 수를 줄이고 해결하고, 나머지(컬렉션) 는 hibernate.default_batch_fetch_size 로 최적화하자.
# 결론 : ToOne 관계는 페치조인해도 페이징에 영향을 주지 않는다. 따라서 ToOne 관계는 페치조인으로 쿼리 수를 줄이고 해결하고, 나머지(컬렉션) 는 hibernate.default_batch_fetch_size 로 최적화하자.
# 결론 : ToOne 관계는 페치조인해도 페이징에 영향을 주지 않는다. 따라서 ToOne 관계는 페치조인으로 쿼리 수를 줄이고 해결하고, 나머지(컬렉션) 는 hibernate.default_batch_fetch_size 로 최적화하자.
default_batch_fetch_size은 그냥 항상 걸어둠.

대부분의 DB가 in쿼리 1000개 넘으면 오류일으킴 그래서 최대값은 1000
숫자 크면 순가부하 증가
숫자 작으면 작게 많이 끊어서 하므로 부하 줄음 -> 시간 늘어남
권장방법 : was-DB 버티면 최대한 크게, 아니면 100정도 놓고 쓰면서 늘리기.
'Java, Spring > 스프링부트와 JPA 활용 2' 카테고리의 다른 글
| 4-6. 주문 조회 V5: JPA에서 DTO 직접 조회 - 컬렉션 조회 최적화 (0) | 2022.09.11 |
|---|---|
| 4-5. 주문 조회 V4: JPA에서 DTO 직접 조회 (1) | 2022.09.11 |
| 질문 모음 (0) | 2022.09.09 |
| 4-3. 주문 조회 V3: 엔티티를 DTO로 변환 - 페치 조인 최적화 (1) | 2022.09.09 |
| 4-2. 주문조회V2:엔티티를 DTO로 변환 (0) | 2022.09.09 |


